The Bourne-Again Shell

위 글은 The Architecture of Open Source Applications (Volume 1)를 번역한 것이다.
3.1 서론
유닉스 셸(Unix shell)은 사용자가 명령어를 실행하여 운영체제와 상호작용할 수 있는 인터페이스를 제공한다. 그러나 셸은 동시에 상당히 풍부한 프로그래밍 언어이기도 하다. 여기에는 제어 흐름, 조건 분기, 반복, 조건문, 기본 수학 연산, 명명된 함수, 문자열 변수, 셸과 실행 명령어 간의 양방향 통신을 위한 구조들이 포함된다.
셸은 xterm과 같은 터미널 또는 터미널 에뮬레이터에서 대화형으로 사용하거나, 파일에서 명령어를 읽어 비대화형으로 사용할 수 있다. bash를 포함한 대부분의 현대 셸은 명령줄 편집 기능을 제공하는데, 이는 입력 중인 명령줄을 emacs나 vi 스타일의 명령어로 조작할 수 있게 해주며, 다양한 형태의 명령어 기록 저장 기능도 포함한다.
Bash의 처리 과정은 셸 파이프라인과 유사하다. 터미널이나 스크립트에서 데이터를 읽은 후, 여러 단계를 거쳐 각 단계마다 변환되며, 최종적으로 셸은 명령어를 실행하고 반환 상태를 수집한다.
이번 장에서는 bash의 주요 구성 요소를 살펴볼 것이다: 입력 처리, 구문 분석, 다양한 단어 확장 및 기타 명령어 처리, 그리고 명령어 실행을 파이프라인 관점에서 다룬다. 이러한 구성 요소들은 키보드나 파일에서 읽은 데이터를 처리하는 파이프라인 역할을 하며, 최종적으로 실행 가능한 명령어로 변환한다.
[Bash 구성 요소 아키텍처]
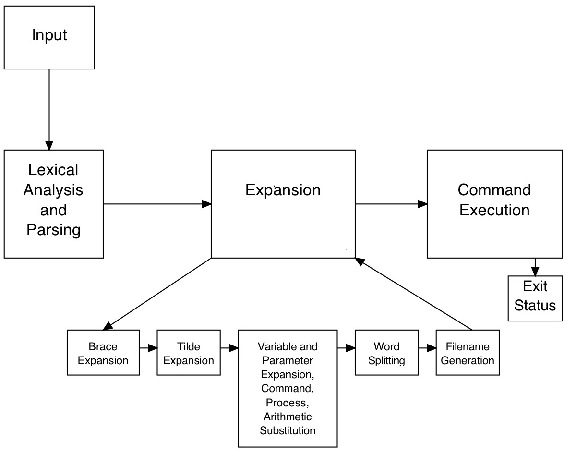
그림 3.1: Bash 구성 요소 아키텍처
3.1.1 Bash
Bash는 GNU 운영체제에서 사용되는 셸로, 일반적으로 Linux 커널을 비롯해 여러 운영체제(특히 Mac OS X)에서 구현된다. 이는 대화형 및 프로그래밍 사용 모두에서 역사적인 sh 버전보다 기능적으로 향상된 점을 제공한다.
이름은 "Bourne-Again SHell"의 두문자어로, 스티븐 본(Stephen Bourne, Bell Labs의 7번째 연구용 유닉스 버전에서 등장한 현대 유닉스 셸 /bin/sh의 직계 조상 저자)의 이름과 재구현을 통한 재탄생이라는 개념을 결합한 말장난이다. bash의 원저자는 프리 소프트웨어 재단(Free Software Foundation)의 직원이었던 브라이언 폭스(Brian Fox)이며, 현재는 오하이주 클리블랜드 소재 케이스 웨스턴 리저브 대학(Case Western Reserve University)에서 근무하는 자원봉사자인 내가 개발 및 유지보수를 담당하고 있다.
다른 GNU 소프트웨어와 마찬가지로 bash는 매우 이식성이 높다. 현재 거의 모든 유닉스 버전과 몇 가지 다른 운영체제에서 실행되며, Cygwin이나 MinGW와 같은 Windows 호환 환경을 위한 독립 지원 포트가 존재한다. 또한 QNX나 Minix와 같은 유닉스 계열 시스템으로의 포트는 배포판의 일부로 포함된다. bash는 Microsoft의 Services for Unix(SFU)와 같은 Posix 환경만 있으면 빌드 및 실행이 가능하다.
3.2. 구문 단위와 기본 요소
3.2.1. 기본 요소
bash에게는 기본적으로 세 종류의 토큰이 있습니다: 예약어, 단어, 그리고 연산자입니다. 예약어는 셸과 프로그래밍 언어에서 의미를 가지는 단어로, 주로 if와 while 같은 흐름 제어 구조를 도입합니다. 연산자는 하나 이상의 메타문자로 구성됩니다: 메타문자는 | 및 > 같이 그 자체로 셸에 특별한 의미를 가지는 문자입니다. 셸 입력의 나머지는 일반 단어로 구성되며, 일부는 명령줄에서 나타나는 위치에 따라 할당문이나 숫자와 같은 특별한 의미를 가집니다.
3.2.2. 변수와 매개변수
모든 프로그래밍 언어와 마찬가지로 셸도 변수를 제공합니다: 저장된 데이터를 참조하고 조작하기 위한 이름입니다. 셸은 기본적인 사용자 설정 변수와 매개변수라고 불리는 일부 내장 변수를 제공합니다. 셸 매개변수는 일반적으로 셸의 내부 상태의 일부를 반영하며, 자동으로 또는 다른 작업의 부작용으로 설정됩니다.
변수 값은 문자열입니다. 일부 값은 문맥에 따라 특별하게 취급되며, 이는 나중에 설명될 것입니다. 변수는 name=value 형식의 문장을 사용하여 할당됩니다. 값은 선택사항입니다; 생략하면 name에 빈 문자열이 할당됩니다. 값이 제공되면 셸은 값을 확장하여 name에 할당합니다. 셸은 변수가 설정되었는지 여부에 따라 다른 작업을 수행할 수 있지만, 값을 할당하는 것만이 변수를 설정하는 유일한 방법입니다. 값이 할당되지 않은 변수는, 선언되고 속성이 부여되었더라도, 설정되지 않은 것으로 간주됩니다.
달러 기호로 시작하는 단어는 변수나 매개변수 참조를 도입합니다. 달러 기호를 포함한 단어는 명명된 변수의 값으로 대체됩니다. 셸은 단순한 값 대체부터 패턴과 일치하는 변수 값의 일부를 변경하거나 제거하는 것까지 다양한 확장 연산자를 제공합니다.
지역 변수와 전역 변수를 위한 조항이 있습니다. 기본적으로 모든 변수는 전역입니다. 어떤 단순 명령(가장 친숙한 명령 유형—명령 이름과 선택적 인수 및 리디렉션 세트)이든 할당 문장 세트를 접두사로 붙여 해당 변수가 해당 명령에 대해서만 존재하도록 할 수 있습니다. 셸은 함수 지역 변수를 가질 수 있는 저장 프로시저 또는 셸 함수를 구현합니다.
변수는 최소한의 타입을 가질 수 있습니다: 단순 문자열 값 변수 외에도 정수와 배열이 있습니다. 정수 타입 변수는 숫자로 취급됩니다: 할당된 문자열은 산술 표현식으로 확장되고 결과가 변수의 값으로 할당됩니다. 배열은 인덱스 또는 연관성이 있을 수 있습니다; 인덱스 배열은 숫자를 첨자로 사용하고, 연관 배열은 임의의 문자열을 사용합니다. 배열 요소는 문자열이며, 필요한 경우 정수로 취급될 수 있습니다. 배열 요소는 다른 배열이 될 수 없습니다.
Bash는 셸 변수를 저장하고 검색하기 위해 해시 테이블을 사용하며, 변수 범위를 구현하기 위해 이러한 해시 테이블의 연결 리스트를 사용합니다. 셸 함수 호출과 명령 앞의 할당 문장에 의해 설정된 변수를 위한 임시 범위에는 다른 변수 범위가 있습니다. 예를 들어, 이러한 할당 문장이 셸에 내장된 명령 앞에 오는 경우, 셸은 변수 참조를 해결하는 정확한 순서를 추적해야 하며, 연결된 범위를 통해 bash가 이를 수행할 수 있습니다. 실행 중첩 수준에 따라 탐색해야 할 범위의 수가 놀라울 정도로 많을 수 있습니다.
3.2.3. 셸 프로그래밍 언어
단순한 셸 명령, 대부분의 독자가 가장 친숙한 명령은 echo나 cd와 같은 명령 이름과 0개 이상의 인수 및 리디렉션 목록으로 구성됩니다. 리디렉션을 통해 셸 사용자는 호출된 명령에 대한 입력과 출력을 제어할 수 있습니다. 위에서 언급했듯이, 사용자는 단순 명령에 로컬인 변수를 정의할 수 있습니다.
예약어는 더 복잡한 셸 명령을 도입합니다. if-then-else, while, 값 목록을 반복하는 for 루프, C와 유사한 산술 for 루프와 같은 모든 고급 프로그래밍 언어에 공통적인 구조가 있습니다. 이러한 더 복잡한 명령을 통해 셸은 명령을 실행하거나 조건을 테스트하고 결과에 따라 다른 작업을 수행하거나, 명령을 여러 번 실행할 수 있습니다.
유닉스가 컴퓨팅 세계에 선사한 선물 중 하나는 파이프라인입니다: 목록의 한 명령의 출력이 다음 명령의 입력이 되는 선형 명령 목록입니다. 어떤 셸 구조도 파이프라인에서 사용될 수 있으며, 명령이 루프에 데이터를 공급하는 파이프라인을 보는 것은 드문 일이 아닙니다.
Bash는 명령이 호출될 때 명령의 표준 입력, 표준 출력, 표준 오류 스트림을 다른 파일이나 프로세스로 리디렉션할 수 있는 기능을 구현합니다. 셸 프로그래머는 리디렉션을 사용하여 현재 셸 환경에서 파일을 열고 닫을 수도 있습니다.
Bash는 셸 프로그램을 저장하고 여러 번 사용할 수 있도록 합니다. 셸 함수와 셸 스크립트는 모두 명령 그룹에 이름을 붙이고 다른 명령을 실행하는 것처럼 그룹을 실행하는 방법입니다. 셸 함수는 특별한 구문을 사용하여 선언되고 같은 셸의 컨텍스트에서 저장 및 실행됩니다; 셸 스크립트는 파일에 명령을 넣고 새로운 셸 인스턴스를 실행하여 해석합니다. 셸 함수는 호출하는 셸과 실행 컨텍스트의 대부분을 공유하지만, 셸 스크립트는 새로운 셸 호출에 의해 해석되므로 환경에서 프로세스 간에 전달되는 것만 공유합니다.
3.2.4. 추가 참고 사항
계속 읽어나가면서, 셸이 몇 가지 데이터 구조만을 사용하여 기능을 구현한다는 점을 염두에 두세요: 배열, 트리, 단일 연결 및 이중 연결 리스트, 그리고 해시 테이블입니다. 거의 모든 셸 구조는 이러한 기본 요소를 사용하여 구현됩니다.
셸이 한 단계에서 다음 단계로 정보를 전달하고, 각 처리 단계 내에서 데이터 단위를 운영하기 위해 사용하는 기본 데이터 구조는 WORD_DESC입니다:
typedef struct word_desc {
char *word; /* 제로로 끝나는 문자열. */
int flags; /* 이 단어와 관련된 플래그. */
} WORD_DESC;
단어는 예를 들어, 단순 연결 리스트를 사용하여 인수 목록으로 결합됩니다:
typedef struct word_list {
struct word_list *next;
WORD_DESC *word;
} WORD_LIST;
WORD_LIST는 셸 전체에 널리 퍼져 있습니다. 단순 명령은 단어 목록이고, 확장의 결과는 단어 목록이며, 내장 명령은 각각 인수의 단어 목록을 취합니다.
3.3. 입력 처리
Bash 처리 파이프라인의 첫 번째 단계는 입력 처리입니다: 터미널이나 파일에서 문자를 읽어 라인으로 분할하고, 이를 셸 파서에 전달하여 명령으로 변환합니다. 예상할 수 있듯이, 라인은 개행 문자(newline)로 종료되는 문자 시퀀스입니다.
3.3.1. Readline과 명령줄 편집
Bash는 대화형 모드일 때 터미널에서 입력을 읽고, 그렇지 않으면 인자로 지정된 스크립트 파일에서 입력을 읽습니다. 대화형 모드에서 Bash는 사용자가 Unix의 emacs 및 vi 편집기와 유사한 친숙한 키 시퀀스와 편집 명령을 사용해 입력 중인 명령줄을 편집할 수 있도록 합니다.
Bash는 Readline 라이브러리를 사용해 명령줄 편집을 구현합니다. 이 라이브러리는 사용자가 명령줄을 편집하고, 입력된 명령줄을 저장하며, 이전 명령을 불러오고, csh-스타일 히스토리 확장을 수행하는 함수 집합을 제공합니다. Bash는 Readline의 주요 클라이언트이며 함께 개발되지만, Readline 자체에는 Bash 전용 코드가 포함되지 않습니다. 많은 다른 프로젝트에서 터미널 기반 라인 편집 인터페이스를 제공하기 위해 Readline을 채택했습니다.
Readline은 또한 사용자가 무제한 길이의 키 시퀀스를 수많은 Readline 명령에 바인딩할 수 있도록 합니다. Readline은 커서 이동, 텍스트 삽입/삭제, 이전 라인 검색, 부분적으로 입력된 단어 완성 등의 명령을 제공합니다. 이를 기반으로 사용자는 매크로를 정의할 수 있습니다. 매크로는 키 시퀀스에 응답하여 명령줄에 삽입되는 문자열로, 키 바인딩과 동일한 구문을 사용합니다. 매크로는 Readline 사용자에게 단순 문자열 치환 및 축약 기능을 제공합니다.
Readline 구조
Readline은 기본적인 읽기/디스패치/실행/재표시 루프로 구조화됩니다. 이는 read 또는 이와 동등한 함수를 사용해 키보드에서 문자를 읽거나 매크로에서 입력을 가져옵니다. 각 문자는 키맵(keymap) 또는 디스패치 테이블의 인덱스로 사용됩니다. 단일 8비트 문자로 인덱싱되지만, 키맵의 각 요소는 여러 가지를 포함할 수 있습니다. 문자는 추가 키맵으로 해석될 수 있으며, 이를 통해 다중 문자 키 시퀀스가 가능해집니다. beginning-of-line과 같은 Readline 명령으로 해석되면 해당 명령이 실행됩니다. self-insert 명령에 바인딩된 문자는 편집 버퍼에 저장됩니다. 또한 키 시퀀스를 명령에 바인딩하면서 하위 시퀀스를 다른 명령에 바인딩하는 것도 가능합니다(상대적으로 최근에 추가된 기능). 이를 나타내기 위해 키맵에 특수 인덱스가 있습니다. 키 시퀀스를 매크로에 바인딩하면 임의의 문자열을 명령줄에 삽입하거나 복잡한 편집 시퀀스를 위한 키보드 단축키를 생성하는 등 높은 유연성을 제공합니다. Readline은 self-insert에 바인딩된 각 문자를 편집 버퍼에 저장하며, 이 버퍼는 화면에 표시될 때 하나 이상의 라인을 차지할 수 있습니다.
Readline은 C char를 사용해 문자 버퍼와 문자열만 관리하며, 필요 시 이를 조합해 멀티바이트 문자를 구성합니다. 속도와 저장 공간 문제, 그리고 멀티바이트 문자 지원이 보편화되기 전에 편집 코드가 존재했기 때문에 내부적으로 wchar_t를 사용하지 않습니다. 멀티바이트 문자를 지원하는 로캘에서 Readline은 전체 멀티바이트 문자를 자동으로 읽어 편집 버퍼에 삽입합니다. 멀티바이트 문자를 편집 명령에 바인딩할 수 있지만, 이러한 문자를 키 시퀀스로 바인딩해야 합니다. 이는 가능하지만 어렵고 일반적으로 원하지 않는 동작입니다. 예를 들어 기존 emacs 및 vi 명령 세트는 멀티바이트 문자를 사용하지 않습니다.
키 시퀀스가 최종적으로 편집 명령으로 해석되면 Readline은 결과를 반영하도록 터미널 표시를 업데이트합니다. 이는 명령이 버퍼에 문자를 삽입하거나, 편집 위치를 이동하거나, 라인을 부분적/완전히 교체하는지 여부와 관계없이 발생합니다. 히스토리 파일을 수정하는 것과 같은 일부 바인딩 가능한 편집 명령은 편집 버퍼의 내용을 변경하지 않습니다.
터미널 표시 업데이트는 겉보기에 단순해 보이지만 상당히 복잡합니다. Readline은 세 가지를 추적해야 합니다: 화면에 표시된 문자 버퍼의 현재 내용, 업데이트된 표시 버퍼의 내용, 실제 표시된 문자. 멀티바이트 문자가 있는 경우 표시된 문자는 버퍼와 정확히 일치하지 않으며, 재표시 엔진은 이를 고려해야 합니다. 재표시 시 Readline은 현재 표시 버퍼의 내용을 업데이트된 버퍼와 비교하고 차이점을 파악한 후, 업데이트된 버퍼를 반영하기 위해 화면을 가장 효율적으로 수정하는 방법을 결정해야 합니다. 이 문제는 수년간 상당한 연구 주제였습니다(문자열-문자열 보정 문제). Readline의 접근 방식은 버퍼의 차이가 발생하는 부분의 시작과 끝을 식별하고, 커서를 앞뒤로 이동하는 비용을 포함해 해당 부분만 업데이트하는 비용을 계산한 후(예: 문자 삭제 및 새 문자 삽입 터미널 명령을 발행하는 것이 현재 화면 내용을 덮어쓰는 것보다 더 많은 노력이 필요한지 여부), 최저 비용 업데이트를 수행하고 필요한 경우 라인 끝에 남은 문자를 제거한 후 커서를 올바른 위치에 배치하는 것입니다.
재표시 엔진은 의심의 여지 없이 Readline에서 가장 많이 수정된 부분입니다. 대부분의 변경 사항은 기능 추가—가장 중요한 것은 프롬프트에 비표시 문자(예: 색상 변경)를 포함하는 기능과 여러 바이트를 차지하는 문자 처리 기능—를 위한 것이었습니다.
Readline은 편집 버퍼의 내용을 호출 애플리케이션에 반환하며, 애플리케이션은 수정 가능한 결과를 히스토리 목록에 저장할 책임이 있습니다.
애플리케이션의 Readline 확장
Readline이 사용자에게 Readline의 기본 동작을 사용자 정의하고 확장할 수 있는 다양한 방법을 제공하는 것처럼, 애플리케이션이 기본 기능 세트를 확장할 수 있는 여러 메커니즘을 제공합니다. 첫째, 바인딩 가능한 Readline 함수는 표준 인자 집합을 받아 지정된 결과 집합을 반환하므로 애플리케이션이 애플리케이션 전용 함수로 Readline을 쉽게 확장할 수 있습니다. 예를 들어 Bash는 Bash 전용 단어 완성부터 셸 내장 명령 인터페이스까지 30개 이상의 바인딩 가능한 명령을 추가합니다.
둘째, Readline은 잘 알려진 이름과 호출 인터페이스를 가진 **후크 함수(hook function)**에 대한 포인터를 광범위하게 사용해 애플리케이션이 동작을 수정할 수 있도록 합니다. 애플리케이션은 Readline의 내부 일부를 교체하거나, Readline 앞에 기능을 끼워 넣거나, 애플리케이션 전용 변환을 수행할 수 있습니다.
3.3.2. 비대화형 입력 처리
셸이 Readline을 사용하지 않을 때는 stdio 또는 자체 버퍼링된 입력 루틴을 사용해 입력을 얻습니다. Bash 버퍼링 입력 패키지는 셸이 대화형이 아닐 때 stdio보다 선호됩니다. 이는 Posix가 입력 소비에 부과하는 다소 특이한 제한 사항 때문입니다: 셸은 명령을 파싱하는 데 필요한 입력만 소비하고 나머지는 실행 프로그램을 위해 남겨둬야 합니다. 이는 셸이 표준 입력에서 스크립트를 읽을 때 특히 중요합니다. 셸은 파서가 소비한 마지막 문자 바로 뒤로 파일 오프셋을 되감을 수 있는 한 입력을 원하는 만큼 버퍼링할 수 있습니다. 실제적으로 이는 셸이 파이프와 같은 탐색 불가능(non-seekable) 장치에서 읽을 때 문자 단위로 스크립트를 읽어야 하지만, 파일에서 읽을 때는 원하는 만큼 버퍼링할 수 있음을 의미합니다.
이러한 특이점을 제외하면 셸 처리의 비대화형 입력 부분의 출력은 Readline과 동일합니다: 개행 문자로 종료되는 문자 버퍼.
3.3.3. 멀티바이트 문자
멀티바이트 문자 처리는 셸의 초기 구현 이후 오랜 시간이 지나 추가되었으며, 기존 코드에 미치는 영향을 최소화하는 방식으로 수행되었습니다. 멀티바이트 문자를 지원하는 로캘에서 셸은 입력을 바이트(C char) 버퍼에 저장하지만, 이 바이트를 잠재적 멀티바이트 문자로 취급합니다. Readline은 멀티바이트 문자를 표시하는 방법(화면 위치 수 계산, 화면에 문자를 표시할 때 버퍼에서 소비할 바이트 수 파악), 바이트 단위가 아닌 문자 단위로 라인을 앞뒤로 이동하는 방법 등을 이해합니다. 그 외에는 멀티바이트 문자가 셸 입력 처리에 큰 영향을 미치지 않습니다. 후반부에 설명할 셸의 다른 부분은 멀티바이트 문자를 인식하고 입력 처리 시 이를 고려해야 합니다.
3.4. 구문 분석
파서 엔진의 초기 작업은 어휘 분석(lexical analysis)입니다: 문자 스트림을 단어로 분리하고 결과에 의미를 부여하는 것입니다. 단어(word)는 파서가 작동하는 기본 단위입니다. 단어는 공백이나 탭과 같은 단순 구분자, 또는 세미콜론과 앰퍼샌드와 같이 셸 언어에 특별한 의미를 가진 **메타문자(metacharacters)**로 구분된 문자 시퀀스입니다.
Tom Duff가 Plan 9 셸인 rc에 대한 논문에서 언급했듯이, 셸의 역사적 문제 중 하나는 Bourne 셸 문법이 실제로 무엇인지 아무도 정확히 모른다는 것입니다. Posix 셸 위원회는 수많은 문맥 의존성을 포함하지만 최종적으로 Unix 셸에 대한 명확한 문법을 공개한 공로가 큽니다. 이 문법은 역사적인 Bourne 셸 파서가 오류 없이 수용해 온 일부 구문을 허용하지 않는 등의 문제가 있지만, 현재 우리가 가진 최선의 결과입니다.
Bash 파서는 Posix 문법의 초기 버전에서 파생되었으며, Yacc 또는 Bison을 사용해 구현된 유일한 Bourne 스타일 셸 파서입니다. 이는 셸 문법이 Yacc 스타일 구문 분석에 잘 맞지 않으며 복잡한 어휘 분석과 파서-어휘 분석기 간의 긴밀한 협력이 필요하기 때문에 자체적인 어려움을 야기했습니다.
어쨌든, 어휘 분석기(lexical analyzer)는 Readline 또는 다른 소스에서 입력 라인을 가져와 메타문자에서 토큰으로 분리하고, 문맥을 기반으로 토큰을 식별한 후 파서에 전달하여 문장과 명령으로 조립합니다. 여기에는 많은 문맥 의존성이 포함됩니다. 예를 들어, 단어 for는 예약어, 식별자, 할당문의 일부 또는 기타 단어가 될 수 있으며, 다음 명령은 완벽히 유효합니다:
for for in for; do for=for; done; echo $for
이 명령은 for를 출력합니다.
이 시점에서 별칭(alias)에 대한 간단한 설명이 필요합니다. Bash는 단순 명령의 첫 번째 단어를 임의의 텍스트로 대체할 수 있도록 허용합니다. 별칭은 완전히 어휘적(lexical)이므로 셸 문법을 변경하는 데 사용(또는 남용)될 수도 있습니다. Bash가 제공하지 않는 복합 명령을 구현하는 별칭을 작성할 수 있습니다. Bash 파서는 별칭 확장을 완전히 어휘 단계에서 구현하지만, 파서는 별칭 확장이 허용되는 시기를 분석기에 알려야 합니다.
많은 프로그래밍 언어와 마찬가지로 셸은 특수한 의미를 제거하기 위해 문자를 이스케이프(escape)할 수 있습니다. 이스케이프에는 세 가지 유형의 인용(quoting)이 있으며, 각각 약간 다른 방식으로 인용된 텍스트를 해석합니다:
- 백슬래시(
\): 다음 문자를 이스케이프합니다. - 작은따옴표(
'): 묶인 모든 문자 해석을 방지합니다. - 큰따옴표(
"): 일부 해석을 방지하지만 특정 단어 확장을 허용합니다(백슬래시 처리도 다름).
어휘 분석기는 인용된 문자와 문자열을 해석하여 파서가 예약어나 메타문자로 인식하지 못하게 합니다. 또한 $'…'와 $"…" 두 가지 특별한 경우가 있습니다:
$'…': ANSI C 문자열과 동일한 방식으로 백슬래시 이스케이프 문자를 확장합니다.$"…": 표준 국제화 함수를 사용해 문자를 번역할 수 있도록 허용합니다.
전자는 널리 사용되지만, 후자는 좋은 예시나 사용 사례가 부족해 덜 사용됩니다.
파서와 어휘 분석기의 상호작용
파서는 일정량의 상태를 인코딩하고 이를 분석기와 공유하여 문법이 요구하는 문맥 의존적 분석을 가능하게 합니다. 예를 들어, 어휘 분석기는 단어를 토큰 유형에 따라 분류합니다: 예약어(적절한 문맥에서), 단어, 할당문 등. 이를 위해 파서는 명령 파싱 진행 상황, 다중 라인 문자열(heredoc) 처리 여부, case 문 또는 조건부 명령 내부 여부, 확장 셸 패턴 또는 복합 할당문 처리 여부 등을 분석기에 알려야 합니다.
명령 치환(command substitution)의 끝을 인식하는 작업의 상당 부분은 parse_comsub 함수에 캡슐화됩니다. 이 함수는 셸 구문을 과도하게 알고 있으며 최적보다 많은 토큰 읽기 코드를 중복합니다. Heredoc, 셸 주석, 메타문자, 단어 경계, 인용, 예약어 허용 시점(예: case 문 내부)을 이해해야 하며, 이를 정확히 구현하는 데 시간이 걸렸습니다.
단어 확장 중 명령 치환을 확장할 때 Bash는 파서를 사용해 구문의 올바른 끝을 찾습니다. 이는 문자열을 eval 명령으로 변환하는 것과 유사하지만, 이 경우 명령은 문자열 끝으로 종료되지 않습니다. 이를 위해 파서는 오른쪽 괄호())를 유효한 명령 종료자로 인식해야 하며, 이는 여러 문법 생성 규칙에서 특수한 경우를 발생시키고 어휘 분석기가 오른쪽 괄호(적절한 문맥에서)를 EOF로 표시하도록 요구합니다. 또한 파서는 재귀적으로 yyparse를 호출하기 전후로 상태를 저장/복원해야 합니다. 명령 치환은 명령 입력 중 프롬프트 문자열 확장의 일부로 파싱 및 실행될 수 있기 때문입니다. 입력 함수는 미리 읽기(read-ahead)를 구현하므로, 이 함수는 Bash가 문자열, 파일 또는 Readline을 통해 터미널에서 입력을 읽는 경우 입력 포인터를 올바른 위치로 되감아야 합니다. 이는 입력이 손실되지 않을 뿐만 아니라 명령 치환 확장 함수가 실행을 위한 정확한 문자열을 구성하는 데 중요합니다.
프로그래밍 가능한 단어 완성(programmable word completion)도 유사한 문제를 제기합니다. 이는 다른 명령을 파싱하는 동안 임의의 명령을 실행할 수 있도록 허용하며, 파서 상태를 저장/복원함으로써 해결됩니다.
인용(quoting)은 호환성 문제와 논쟁의 원인입니다. 첫 번째 Posix 셸 표준이 공개된 지 20년이 지났음에도 표준 작업 그룹은 여전히 모호한 인용의 올바른 동작을 논의하고 있습니다. Bourne 셸은 동작 관찰을 위한 참조 구현 외에는 도움이 되지 않습니다.
파서는 명령을 나타내는 단일 C 구조체(루프와 같은 복합 명령의 경우 다른 명령을 포함할 수 있음)를 반환하고, 이를 셸 운영의 다음 단계인 단어 확장(word expansion)으로 전달합니다. 명령 구조체는 명령 객체와 단어 목록으로 구성됩니다. 대부분의 단어 목록은 다음 섹션에서 설명할 문맥에 따라 다양한 변환을 거칩니다.
3.5. 단어 확장(Word Expansions)
구문 분석 후, 실행 전에, 구문 분석 단계에서 생성된 많은 단어들은 하나 이상의 단어 확장 과정을 거치게 됩니다. 이를 통해 (예를 들어) $OSTYPE은 "linux-gnu" 문자열로 대체됩니다.
3.5.1. 매개변수 및 변수 확장
변수 확장은 사용자들이 가장 친숙하게 느끼는 확장입니다. 쉘 변수는 거의 타입이 없으며, 몇 가지 예외를 제외하고는 문자열로 취급됩니다. 확장은 이러한 문자열을 확장하고 변환하여 새로운 단어와 단어 목록으로 만듭니다.
변수의 값 자체에 작용하는 확장들이 있습니다. 프로그래머는 이를 사용하여 변수 값의 부분 문자열, 값의 길이를 생성하거나, 지정된 패턴과 일치하는 부분을 처음이나 끝에서 제거하거나, 지정된 패턴과 일치하는 부분을 새 문자열로 대체하거나, 변수 값의 알파벳 문자의 대소문자를 수정할 수 있습니다.
또한 변수의 상태에 따라 달라지는 확장도 있습니다. 변수가 설정되었는지 여부에 따라 다른 확장이나 할당이 이루어집니다. 예를 들어, ${parameter:-word}는 parameter가 설정되어 있으면 parameter로 확장되고, 설정되어 있지 않거나 빈 문자열로 설정된 경우에는 word로 확장됩니다.
3.5.2. 그 외 다양한 확장
Bash는 각각 독특한 규칙을 가진 많은 다른 종류의 확장을 수행합니다. 처리 순서상 첫 번째는 중괄호 확장으로, 다음과 같이 변환합니다:
pre{one,two,three}post
다음으로 변환됩니다:
preonepost pretwopost prethreepost
또한 명령어 치환(command substitution)도 있는데, 이는 명령어를 실행하고 변수를 조작하는 쉘의 능력을 잘 결합한 것입니다. 쉘은 명령어를 실행하고, 출력을 수집한 다음, 그 출력을 확장의 값으로 사용합니다.
명령어 치환의 문제 중 하나는 명령어를 즉시 실행하고 완료될 때까지 기다린다는 것입니다. 쉘이 명령어에 입력을 보낼 쉬운 방법이 없습니다. Bash는 프로세스 치환(process substitution)이라는 기능을 사용하여 이러한 단점을 보완합니다. 이는 명령어 치환과 쉘 파이프라인의 조합과 같습니다. 명령어 치환과 마찬가지로 bash는 명령어를 실행하지만, 백그라운드에서 실행되도록 하고 완료를 기다리지 않습니다. 핵심은 bash가 읽기 또는 쓰기를 위해 명령어에 파이프를 열고 이를 파일 이름으로 노출하여 확장의 결과가 되도록 한다는 것입니다.
다음은 틸드 확장(tilde expansion)입니다. 원래는 ~alan을 Alan의 홈 디렉토리 참조로 바꾸기 위한 것이었으나, 수년에 걸쳐 다양한 디렉토리를 참조하는 방법으로 발전했습니다.
마지막으로 산술 확장(arithmetic expansion)이 있습니다. $((expression))은 C 언어 표현식과 동일한 규칙에 따라 표현식을 평가하게 합니다. 표현식의 결과가 확장의 결과가 됩니다.
변수 확장은 작은따옴표와 큰따옴표의 차이가 가장 분명하게 드러나는 곳입니다. 작은따옴표는 모든 확장을 억제합니다—따옴표로 둘러싸인 문자들은 확장 과정을 온전히 통과합니다—반면 큰따옴표는 일부 확장을 허용하고 다른 확장은 억제합니다. 단어 확장과 명령어, 산술, 프로세스 치환은 발생합니다—큰따옴표는 결과가 처리되는 방식에만 영향을 미칩니다—하지만 중괄호와 틸드 확장은 발생하지 않습니다.
3.5.3. 단어 분할
단어 확장의 결과는 쉘 변수 IFS의 값에 있는 문자를 구분자로 사용하여 분할됩니다. 이것이 쉘이 하나의 단어를 여러 개로 변환하는 방법입니다. $IFS의 문자 중 하나가 결과에 나타날 때마다 bash는 단어를 둘로 분할합니다. 작은따옴표와 큰따옴표 모두 단어 분할을 억제합니다.
3.5.4. 글로빙
결과가 분할된 후, 쉘은 이전 확장에서 나온 각 단어를 잠재적 패턴으로 해석하고 선행 디렉토리 경로를 포함한 기존 파일 이름과 일치시키려고 시도합니다.
3.5.5. 구현
쉘의 기본 아키텍처가 파이프라인과 병렬을 이룬다면, 단어 확장은 그 자체로 작은 파이프라인입니다. 단어 확장의 각 단계는 단어를 가져와서 가능하게 변환한 후 다음 확장 단계로 전달합니다. 모든 단어 확장이 수행된 후에 명령어가 실행됩니다.
bash의 단어 확장 구현은 이미 설명한 기본 데이터 구조를 기반으로 합니다. 파서에서 출력된 단어들은 개별적으로 확장되어 입력 단어마다 하나 이상의 단어가 생성됩니다. WORD_DESC 데이터 구조는 단일 단어의 확장을 캡슐화하는 데 필요한 모든 정보를 보유할 수 있을 만큼 다재다능함이 입증되었습니다. 플래그는 단어 확장 단계 내에서 사용할 정보를 인코딩하고 한 단계에서 다음 단계로 정보를 전달하는 데 사용됩니다. 예를 들어, 파서는 특정 단어가 쉘 할당 명령문임을 확장 및 명령 실행 단계에 알리기 위해 플래그를 사용하고, 단어 확장 코드는 내부적으로 플래그를 사용하여 단어 분할을 억제하거나 인용된 null 문자열("$x", $x가 설정되지 않았거나 null 값을 가진 경우)의 존재를 기록합니다. 각 확장 단어에 대해 단일 문자 문자열을 사용하고 추가 정보를 나타내기 위해 일종의 문자 인코딩을 사용하는 것은 훨씬 더 어려웠을 것입니다.
파서와 마찬가지로, 단어 확장 코드는 표현에 한 바이트 이상이 필요한 문자를 처리합니다. 예를 들어, 변수 길이 확장(${#variable})은 바이트가 아닌 문자 단위로 길이를 계산하며, 코드는 다중 바이트 문자가 있는 경우에도 확장의 끝이나 확장에 특별한 문자를 올바르게 식별할 수 있습니다.
3.6. 명령어 실행
bash 내부 파이프라인의 명령어 실행 단계는 실제 동작이 발생하는 곳입니다. 대부분의 경우, 확장된 단어 집합은 명령어 이름과 인수 집합으로 분해되어 운영 체제에 파일로 전달되어 읽고 실행되며, 나머지 단어는 argv 요소의 나머지 부분으로 전달됩니다.
지금까지의 설명은 의도적으로 Posix가 단순 명령어(simple commands)라고 부르는 것에 집중했습니다—명령어 이름과 인수 집합이 있는 것들입니다. 이것이 가장 일반적인 명령어 유형이지만, bash는 훨씬 더 많은 기능을 제공합니다.
명령어 실행 단계의 입력은 파서가 구축한 명령어 구조와 가능하게 확장된 단어 집합입니다. 이곳이 실제 bash 프로그래밍 언어가 작동하는 곳입니다. 프로그래밍 언어는 앞서 논의한 변수와 확장을 사용하며, 고수준 언어에서 기대할 수 있는 구조를 구현합니다: 루프, 조건문, 대안, 그룹화, 선택, 패턴 매칭에 기반한 조건부 실행, 표현식 평가, 그리고 쉘에 특화된 몇 가지 고수준 구조들이 있습니다.
3.6.1. 리다이렉션
운영 체제의 인터페이스로서의 쉘의 역할을 반영하는 것 중 하나는 호출하는 명령어의 입력과 출력을 리다이렉트하는 능력입니다. 리다이렉션 구문은 쉘의 초기 사용자들의 정교함을 보여주는 것 중 하나입니다. 최근까지도 사용자들은 사용 중인 파일 디스크립터를 추적하고, 표준 입력, 출력, 오류 이외의 것을 명시적으로 숫자로 지정해야 했습니다.
리다이렉션 구문에 최근 추가된 기능은 사용자가 직접 파일 디스크립터를 선택하는 대신 쉘이 적절한 파일 디스크립터를 선택하여 지정된 변수에 할당하도록 지시할 수 있게 해줍니다. 이는 파일 디스크립터를 추적해야 하는 프로그래머의 부담을 줄이지만, 추가 처리가 필요합니다: 쉘은 올바른 위치에서 파일 디스크립터를 복제하고, 지정된 변수에 할당되도록 해야 합니다. 이는 어휘 분석기에서 파서를 통해 명령어 실행에 이르기까지 정보가 전달되는 또 다른 예입니다: 분석기는 단어를 변수 할당을 포함한 리다이렉션으로 분류합니다; 파서는 적절한 문법 생성에서 할당이 필요함을 나타내는 플래그와 함께 리다이렉션 객체를 생성합니다; 그리고 리다이렉션 코드는 플래그를 해석하고 파일 디스크립터 번호가 올바른 변수에 할당되도록 합니다.
리다이렉션을 구현하는 가장 어려운 부분은 리다이렉션을 취소하는 방법을 기억하는 것입니다. 쉘은 파일 시스템에서 실행되어 새 프로세스를 생성하는 명령어와 쉘 자체가 실행하는 명령어(빌트인) 사이의 구분을 의도적으로 흐리게 하지만, 명령어가 어떻게 구현되든 관계없이 리다이렉션의 효과는 명령어 완료 이후에도 지속되지 않아야 합니다. 따라서 쉘은 각 리다이렉션의 효과를 취소하는 방법을 추적해야 합니다. 그렇지 않으면 쉘 빌트인 명령어의 출력을 리다이렉트하면 쉘의 표준 출력이 변경될 것입니다. Bash는 할당한 파일 디스크립터를 닫거나, 복제되고 있는 파일 디스크립터를 저장했다가 나중에 dup2를 사용하여 복원하는 등의 방법으로 각 유형의 리다이렉션을 취소하는 방법을 알고 있습니다. 이것들은 파서가 생성한 것과 동일한 리다이렉션 객체를 사용하며 동일한 함수를 사용하여 처리됩니다.
여러 리다이렉션은 객체의 단순 목록으로 구현되므로, 취소에 사용되는 리다이렉션은 별도의 목록에 보관됩니다. 이 목록은 명령어가 완료될 때 처리되지만, 쉘 함수나 "." 빌트인에 연결된 리다이렉션은 해당 함수나 빌트인이 완료될 때까지 유지되어야 하므로 쉘은 그렇게 할 때 주의해야 합니다. 명령어를 호출하지 않을 때, exec 빌트인은 취소 목록을 단순히 폐기하게 만듭니다. 왜냐하면 exec와 관련된 리다이렉션은 쉘 환경에서 유지되기 때문입니다.
또 다른 복잡성은 bash가 스스로 초래한 것입니다. Bourne 쉘의 역사적인 버전은 사용자가 파일 디스크립터 0-9만 조작할 수 있게 허용하고, 디스크립터 10 이상은 쉘의 내부 용도로 예약했습니다. Bash는 이 제한을 완화하여 사용자가 프로세스의 열린 파일 제한까지 모든 디스크립터를 조작할 수 있게 했습니다. 이는 bash가 외부 라이브러리에 의해 직접 열린 것을 포함하여 자체 내부 파일 디스크립터를 추적하고, 요청에 따라 이동할 준비가 되어 있어야 함을 의미합니다. 이는 많은 북키핑, close-on-exec 플래그와 관련된 일부 휴리스틱, 그리고 명령어 기간 동안 유지되었다가 처리되거나 폐기되는 또 다른 리다이렉션 목록이 필요합니다.
3.6.2. 빌트인 명령어
Bash는 여러 명령어를 쉘 자체의 일부로 만듭니다. 이러한 명령어는 새 프로세스를 생성하지 않고 쉘에 의해 실행됩니다.
명령어를 빌트인으로 만드는 가장 일반적인 이유는 쉘의 내부 상태를 유지하거나 수정하기 위해서입니다. cd는 좋은 예입니다; Unix 입문 수업에서 전형적인 연습 중 하나는 cd가 외부 명령어로 구현될 수 없는 이유를 설명하는 것입니다.
Bash 빌트인은 쉘의 나머지 부분과 동일한 내부 기본 요소를 사용합니다. 각 빌트인은 단어 목록을 인수로 받는 C 언어 함수를 사용하여 구현됩니다. 단어는 단어 확장 단계에서 출력된 것입니다; 빌트인은 이를 명령어 이름과 인수로 취급합니다. 대부분의 경우, 빌트인은 다른 명령어와 동일한 표준 확장 규칙을 사용하지만, 몇 가지 예외가 있습니다: 할당 문을 인수로 받아들이는 bash 빌트인(예: declare 및 export)은 할당 인수에 대해 쉘이 변수 할당에 사용하는 것과 동일한 확장 규칙을 사용합니다. 이는 WORD_DESC 구조의 flags 멤버가 쉘의 내부 파이프라인의 한 단계에서 다른 단계로 정보를 전달하는 데 사용되는 한 예입니다.
3.6.3. 단순 명령어 실행
단순 명령어는 가장 일반적으로 만나는 것입니다. 파일 시스템에서 읽은 명령어의 검색 및 실행, 그리고 종료 상태 수집은 쉘의 남은 많은 기능을 다룹니다.
쉘 변수 할당(즉, var=value 형태의 단어)은 그 자체로 일종의 단순 명령어입니다. 할당 문은 명령어 이름 앞에 오거나 명령어 줄에 단독으로 있을 수 있습니다. 명령어 앞에 오면, 변수는 실행되는 명령어의 환경으로 전달됩니다(빌트인 명령어나 쉘 함수 앞에 오면, 몇 가지 예외를 제외하고 빌트인이나 함수가 실행되는 동안만 유지됩니다). 명령어 이름이 뒤따르지 않으면, 할당 문은 쉘의 상태를 수정합니다.
쉘 함수나 빌트인의 이름이 아닌 명령어 이름이 제시되면, bash는 그 이름을 가진 실행 파일을 파일 시스템에서 검색합니다. PATH 변수의 값은 검색할 디렉토리의 콜론으로 구분된 목록으로 사용됩니다. 슬래시(또는 다른 디렉토리 구분자)를 포함하는 명령어 이름은 조회되지 않고 직접 실행됩니다.
PATH 검색을 사용하여 명령어를 찾으면, bash는 명령어 이름과 해당하는 전체 경로명을 해시 테이블에 저장하고, 이후 PATH 검색을 수행하기 전에 이 테이블을 참조합니다. 명령어를 찾을 수 없으면, bash는 특별히 명명된 함수가 정의되어 있는 경우, 명령어 이름과 인수를 함수의 인수로 하여 이 함수를 실행합니다. 일부 Linux 배포판은 이 기능을 사용하여 누락된 명령어를 설치할 것을 제안합니다.
bash가 실행할 파일을 찾으면, 분기하여 새로운 실행 환경을 만들고, 이 새로운 환경에서 프로그램을 실행합니다. 실행 환경은 신호 처리 방식과 리다이렉션에 의해 열리고 닫힌 파일과 같은 사소한 수정을 제외하고는 쉘 환경의 정확한 복제본입니다.
3.6.4. 작업 제어
쉘은 명령어를 전경에서 실행할 수 있으며, 이 경우 명령어가 완료될 때까지 기다리고 종료 상태를 수집하거나, 백그라운드에서 실행할 수 있으며, 이 경우 쉘은 즉시 다음 명령어를 읽습니다. 작업 제어는 프로세스(실행 중인 명령어)를 전경과 백그라운드 사이에서 이동하고, 실행을 일시 중지하고 재개하는 능력입니다. 이를 구현하기 위해, bash는 작업이라는 개념을 도입했는데, 이는 본질적으로 하나 이상의 프로세스에 의해 실행되는 명령어입니다. 예를 들어, 파이프라인은 각 요소에 대해 하나의 프로세스를 사용합니다. 프로세스 그룹은 별도의 프로세스를 하나의 작업으로 결합하는 방법입니다. 터미널에는 프로세스 그룹 ID가 연결되어 있으므로, 전경 프로세스 그룹은 프로세스 그룹 ID가 터미널의 ID와 동일한 그룹입니다.
쉘은 작업 제어 구현에 몇 가지 간단한 데이터 구조를 사용합니다. 자식 프로세스를 표현하는 구조체가 있는데, 여기에는 프로세스 ID, 상태, 그리고 종료 시 반환한 상태가 포함됩니다. 파이프라인은 이러한 프로세스 구조체의 단순한 연결 리스트입니다. 작업도 상당히 유사합니다: 프로세스 목록, 일부 작업 상태(실행 중, 일시 중지됨, 종료됨 등), 그리고 작업의 프로세스 그룹 ID가 있습니다. 프로세스 목록은 일반적으로 단일 프로세스로 구성됩니다; 파이프라인만이 작업과 연관된 둘 이상의 프로세스를 갖게 됩니다. 각 작업은 고유한 프로세스 그룹 ID를 가지며, 작업 내에서 프로세스 ID가 작업의 프로세스 그룹 ID와 동일한 프로세스를 프로세스 그룹 리더라고 합니다. 현재 작업 세트는 배열에 보관되며, 개념적으로 사용자에게 표시되는 방식과 매우 유사합니다. 작업의 상태와 종료 상태는 구성 프로세스의 상태와 종료 상태를 집계하여 조립됩니다.
쉘의 다른 여러 요소와 마찬가지로, 작업 제어를 구현하는 데 있어 복잡한 부분은 북키핑입니다. 쉘은 프로세스를 올바른 프로세스 그룹에 할당하고, 자식 프로세스 생성과 프로세스 그룹 할당이 동기화되도록 하며, 터미널의 프로세스 그룹이 적절하게 설정되도록 주의해야 합니다. 터미널의 프로세스 그룹은 전경 작업을 결정하기 때문입니다(그리고 쉘의 프로세스 그룹으로 다시 설정되지 않으면, 쉘 자체가 터미널 입력을 읽을 수 없게 됩니다). 이는 프로세스 지향적이기 때문에, while과 for 루프와 같은 복합 명령어를 전체 루프를 하나의 단위로 중지하고 시작할 수 있도록 구현하는 것은 간단하지 않으며, 몇몇 쉘만이 이를 구현했습니다.
3.6.5. 복합 명령어
복합 명령어는 하나 이상의 단순 명령어 목록으로 구성되며 if나 while과 같은 키워드로 시작됩니다. 이는 쉘의 프로그래밍 능력이 가장 잘 보이고 효과적인 곳입니다.
구현은 상당히 예상대로입니다. 파서는 다양한 복합 명령어에 해당하는 객체를 구성하고, 객체를 순회하여 해석합니다. 각 복합 명령어는 적절한 확장을 수행하고, 지정된 대로 명령어를 실행하며, 명령어의 반환 상태에 따라 실행 흐름을 변경하는 역할을 하는 해당 C 함수에 의해 구현됩니다. for 명령어를 구현하는 함수가 예시입니다. 먼저 in 예약어 다음에 오는 단어 목록을 확장해야 합니다. 그런 다음 함수는 확장된 단어를 통해 반복하여, 각 단어를 적절한 변수에 할당한 다음 for 명령어 본문의 명령어 목록을 실행해야 합니다. for 명령어는 명령어의 반환 상태에 따라 실행을 변경할 필요는 없지만 break와 continue 빌트인의 효과에 주의를 기울여야 합니다. 목록의 모든 단어가 사용되면 for 명령어는 반환합니다. 이는 대부분 구현이 설명을 매우 밀접하게 따른다는 것을 보여줍니다.